I research artificial intelligence in astronomy. I am funded through the Alan Turing Institute (the UK’s national institute for data science and artificial intelligence) and the STFC’s 4IR CDT.
This page is not a technical overview, and is written to be a generalist introduction to some of the concepts involved in my research.
Motivation
Astronomy has been driven by the understanding of data from its conception as a tool for navigation and agriculture through to the 21st century. In modern astronomy, the expanse of the universe allows us to probe the most extreme environments in existence to help us garner a better understanding of … well pretty much everything.
With enormous volumes of data being generated by the newest astronomical instruments and even more data expected from instruments being built, this is truly the era of big (and I mean big big) data astronomy.
And that’s where my research comes in.
AI & Data science
I research AI methods to combat and extract scientific value from the overwhelming volumes of data which modern astronomical instruments produce.
AI Research
My research has encapsulated a number of ideas. I am interested in the fundamentals of improving AI, developing methods to improve the robustness of common approaches for scientific applications, and effectively mapping high dimensional data using human expertise to constrain AI models.
My research has included:
- Self-attention as explainable AI,
- Equivariant convolutional neural networks,
- Natural language approaches to semantic classification,
- Data Augmentations as domain specific inductive priors.
Some pretty results from my work on 2-dimensional Euclidean equivariant convolutional neural networks include the following two videos. I was considering how model priors can affect the effective explainability and robustness of supervised deep learning self-attention computer vision models, for radio astronomy.
Self-attention maps of models trained to classify radio galaxies. See: Bowles et al. (2021).
Citizen Science and Radio Galaxy Zoo EMU
For those of you wondering how we can use deep learning methodologies for astronomy when they rely on many labels of data points, you are justified in your concern. However, there are currently at least two answers to your concerns.
Firstly, astronomers have been labelling objects for several decades which can give us enough labels to work with in some cases. Secondly, we can learn to make use of so-called citizen scientists. These are people who look at samples of data and provide information on the sample in a fashion which is easy for a human to do, but traditionally impossible for a computer. This concept has been used for many different projects and will be a useful tool in many fields going forwards. My thanks to the citizen scientists working on any project! The portal I am most familiar with, and has been used extensively in astronomy, is zooniverse which hosts projects in a wide variety of domains from art to climate science to astronomy.
I am part of the team led by Hongming Tang and Eleni Vardoulaki working to bring the citizen science project EMU-Zoo to life. This project will provide us with better insight into the droves of data being produced by the EMU survey, and more broadly inform future research in the field of radio astronomy.
Radio Astronomy
So we have our labels and our fancy statistics but where does the actual science image come from? A simple combination of: incredible instrumentation, masterful mathematics and considerable computation.
Instrumentation
The largest limitation of radio telescopes is the diameter of the receiving area and the total collecting area. The three largest steerable radio telescopes are the Lovell Telescope at 76m, Effelsberg at 100m and Green Bank Telescope at 100m. The reason we don’t build bigger is: we can’t. Any bigger and the structure would bend and bow under it’s own weight.
The scientific community has found two complementary solutions to this: either build a single dish in an existing natural structure such as a valley (see the late Arecibo Telescope or FAST), or build a number of smaller telescopes and synthesise an incredible single larger telescope by combining their signals. This telescope synthesis is known as interferometry and is used to synthesise telescopes with much larger effective diameters. This increased size comes at the cost of reduced collecting area in comparison to a full dish of the same size (which cannot exist in our current paradigm).
I process the data collected by an interferometric array into useful scientific data products. Specifically I work on data from MeerKAT whose anntenna are depicted in the banner image at the top of this page.
Mathematics
Without repeating the beautiful and masterful mathematics around synthesising an image from the raw ‘visibilities’ collected by the array, the process is (much simplified) into calibration of the data, flagging erroneous data and transforming the data into an image.
The transformation of the data into an image is sketched out below.
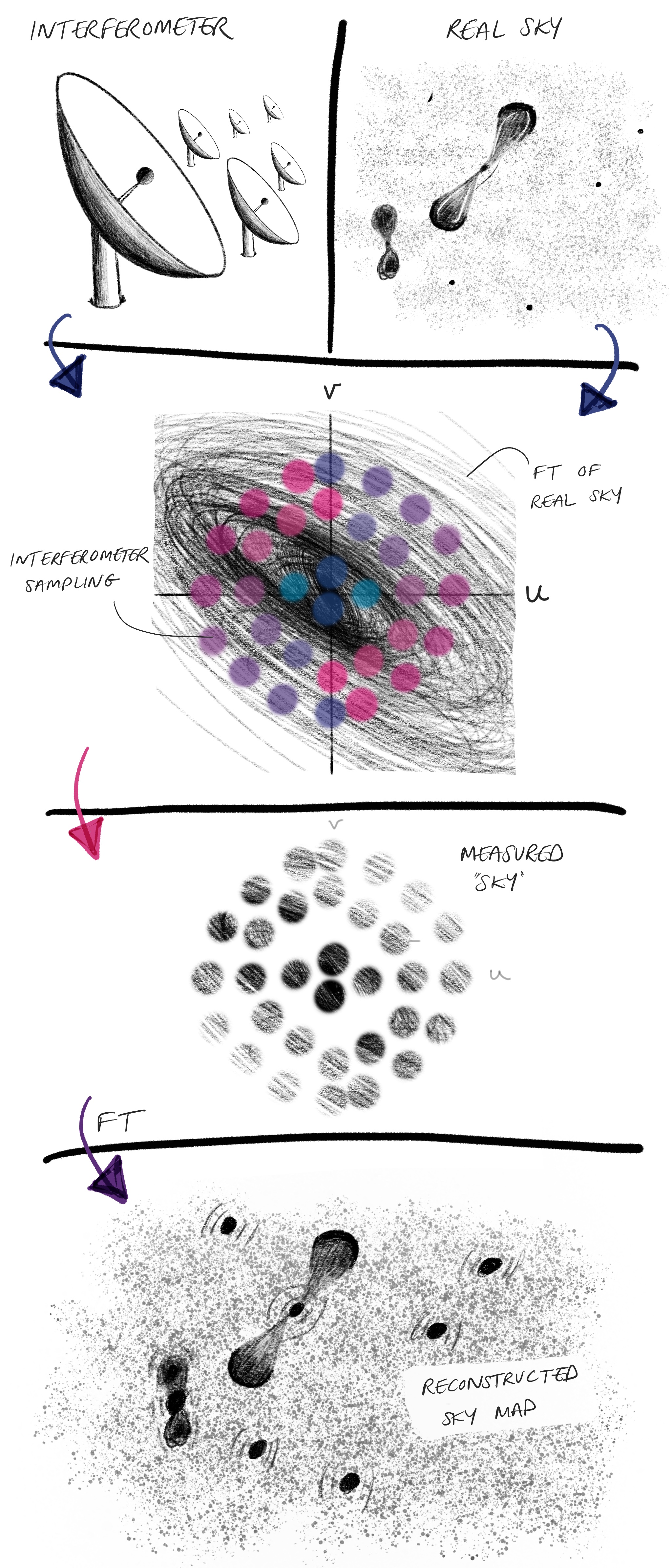
Cartoon schematic of interferometric imaging. FT = Fourrier Transforms. And no, they aren’t real.
My colleagues made me promise to point out that this is a severe simplification: I’m skipping critical steps in scientific imaging as well as the majority of the calculations that likely don’t add much value to the experience of a non-expert reader. Reach out for resources to the real meat of interferometric imaging.
Computation
Considerable copmutation is required to image radio interferometric data at scale. Time for some napkin calculations: The MeerKAT array has up to 32,000 channels, 64 antenna meaning 2,018 baselines, and 4 polarisation products per baseline. Each pointing consists of 8 hours of observations with 8 second intervals. This amounts to: 3200020184*6/(8/602)=6.97 x 109 data points. At 64 bits per data point, each pointing amounts to approximately 45 TB.
We deal with this in a number of ways. After reducing the data to whatever is required by the respective team, the data can be processed using specialised software which we write for specialised hardware. Using high performance computing facilities such as these is non-trivial and is an area of growth in radio astronomy as newer interferometric facilities such as MeerKAT and eventually the SKAO telescopes require leading technical infrastructure to process the data from the respective instruments. For my work, I make use of IDIA’s ILIFU cluster, specialised high memory IRIS nodes, and an HPC facility in my department at JBCA.
Finally, within MeerKAT’s MIGHTEE survey, the data is reduced in science goal specific ways to allow for individual science products to be realised. Each of the science working groups is listed along side the respective chairs here. My work falls within the MIGHTEE Polarisation project.
MIGHTEE-POL
Within the MIGHTEE-POL team, our data is reduced before we receive it to 1k channels, meaning each pointing is ~1.4 TB. We aim to process this into scientifically valuable data products which through the measurements of the polarisation property of the observed radio emission will provide insights into the magnetic properties of our universe. Specifically, we can constrain the magnetic fields of the objects within our fields as well as the magnetic properties of the materials between our telescope and the objects in the four MIGHTEE target fields.
Heywood et al. (2021) figure 3 presents the early science XMMLSS field.
The science products we produce will be released to the public according to the MIGHTEE guidelines. For more information please see the MIGHTEE website. As our work is published I hope to share more details here.
ML Clubs & AI Ethics
In light of my interests, in collaboration with Dr. Alex Clarke and Dr. Philippa Hartley at the SKAO I organise the SKAO-JBCA ML Club. We run this to share ideas and build collaborations. Please see our club’s website for more details on previous sessions and related activity.
I also developed an ML interest group as a collaboration with the astronomy department (DOA) at Tsinghua University. As part of the planning, our committee discussed and developed an ethics statement for ML interest groups to help spread awareness of potential miss-use of ML and to remind participants to be weary of the potential applications of their current and future work. Attempting to encourage each individual to deeply consider what they should do over what they can. To this end, I developed the clear short reminder:
In awareness of ongoing misuse of ML around the world, as a community of participants we commit to practising ethical ML. We will strive to consider our impact on all communities, whether through intentional abuse, or through unintended consequences or biases.
We encouraged our participants to also adhere to, and be aware of, the NeurIPS ethics guidelines as well as the SKAO Code of Conduct as more comprehensive guidelines.